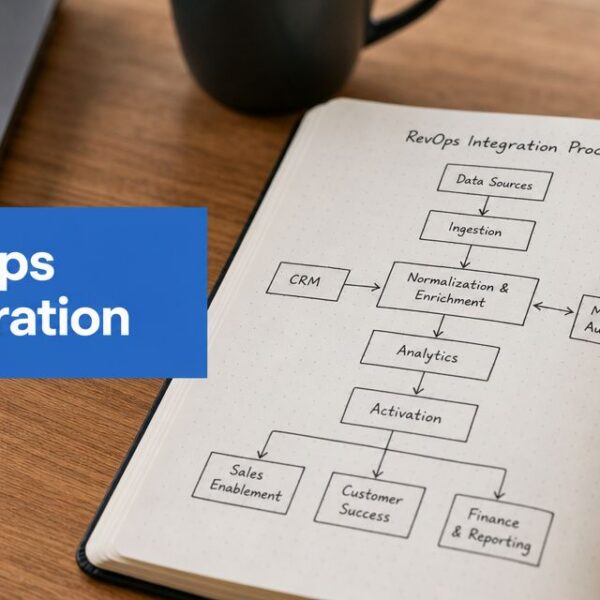
You've probably had this dashboard moment.
Marketing shows strong top-of-funnel volume. Sales says pipeline quality feels off. Leadership sees a clean chart with totals and trend lines, then asks why bookings don't reflect the same story. Inside Salesforce or HubSpot, every number looks polished, but the operating teams know something is missing.
That disconnect usually isn't a reporting bug. It's a misunderstanding of what the report is showing. Most dashboards are built on aggregate data. That's useful, necessary, and often the only way to make large datasets readable. It's also where RevOps teams get into trouble when summary numbers are treated like complete explanations.
For marketing ops and sales ops managers, the aggregate data definition matters because it sits under nearly every KPI you share: lead volume, pipeline by source, average sales cycle, open cases by team, booked revenue by month, and campaign influence views. If you don't know how those figures were grouped, filtered, and rolled up, you can end up optimising the chart instead of the business.
The RevOps Reporting Paradox
A common reporting pattern looks like this. Lead creation is up, campaign engagement looks healthy, and the dashboard says SDR activity is on track. Yet account executives complain that good opportunities are thin, and the forecast hasn't moved in a way that matches the top-line story.
That's the paradox. The aggregate view can be correct and still be incomplete.
In practice, this happens when teams rely on summary metrics without checking what got compressed into them. A quarterly lead total might combine webinar sign-ups, partner referrals, low-intent content conversions, test records, and recycled leads. The chart isn't lying. It's just answering a narrower question than the team thinks it is.
Aggregate reporting is great at telling you what happened at a group level. It's weaker at telling you why it happened.
In Salesforce, this often shows up in campaign dashboards and opportunity roll-ups. In HubSpot, it appears in lifecycle stage reporting, attribution summaries, and company-level properties built from associated records. The dashboard gives leadership the headline. The ops team still has to diagnose the mechanics underneath it.
What managers usually miss
The problem usually isn't that teams use aggregate data. You have to. No revenue leader wants to read a list of every contact or opportunity one row at a time.
The problem is that teams often skip two questions:
- What records were included
- What detail was lost when they were grouped
Those questions matter more than the metric label itself. “Pipeline by source” sounds precise, but if source values are inconsistent or opportunities inherit source fields unevenly, the aggregate number becomes a polished summary of mixed logic.
Why this matters in daily ops
When marketing ops trusts the aggregate view too much, budget shifts happen too early. When sales ops ignores it entirely, strategic reporting becomes impossible. Good RevOps work sits between those extremes.
You need the summary to direct attention. You need the raw records to validate action. That's the operating discipline behind useful reporting.
Defining Aggregate Data vs Raw Data
The simplest aggregate data definition is this. Aggregate data is information combined into summary form from multiple underlying records. Raw data is the underlying row-level detail.
A legal definition makes that distinction very clear. In U.S. federal regulation, 31 CFR § 800.201 defines aggregated data as data “combined or collected together in summary or other form such that the data cannot be identified with any individual.” That's one reason aggregate data is so common in executive and public reporting. It shows patterns without exposing a single record.
For RevOps teams, the academic wording matters less than the practical translation inside your systems.
How this looks in Salesforce and HubSpot
A raw record is one thing that happened or one object in your CRM:
- one Lead in Salesforce
- one Contact in HubSpot
- one Opportunity tied to an Account
- one support Case
- one form submission
- one campaign member response
An aggregate metric is what you get when those records are grouped, counted, averaged, or summed:
- total MQLs this month
- average deal amount by segment
- open pipeline by owner
- number of deals associated with a company
- total closed won amount by quarter
If you've worked with Salesforce Data Cloud, this distinction becomes even more important because unified profiles and calculated insights can make summary views look more authoritative than the source records that feed them. The output may be cleaner, but the logic still starts at row level.
Raw data vs aggregate data
| Attribute | Raw Data | Aggregate Data |
|---|---|---|
| Level of detail | One record at a time | Many records summarised |
| Typical CRM example | A single opportunity with amount, stage, owner, and close date | Total pipeline by stage or by owner |
| Best use | Investigation, routing, QA, operational follow-up | Dashboards, trends, benchmarking, executive review |
| Main strength | Preserves context and exceptions | Makes large volumes understandable |
| Main limitation | Hard to read at scale | Hides individual variation |
| Common user | Ops analysts, SDR managers, sales managers | RevOps leaders, executives, finance, regional leaders |
A classroom analogy still works
Think of a class exam.
The average exam score is aggregate data. It helps you compare this class to last term or one campus to another. But it won't tell you whether a handful of students failed badly while the rest did well. The individual scores are the raw data.
CRM reporting works the same way. A dashboard tile that says “average sales cycle” is a useful management summary. It doesn't tell you whether enterprise deals are stalling in legal review while SMB deals are moving quickly. You only see that once you leave the aggregate view and inspect the record-level pattern.
Practical rule: use aggregate data to frame the question, then use raw data to answer it well.
Why Aggregation Is the Backbone of Strategic Analytics
Strategic reporting would fall apart without aggregation. Executive teams don't need a spreadsheet of every touchpoint. They need a stable way to see trend direction, compare business units, and make decisions quickly.

Aggregate data has a long history in statistics and economics for describing populations, and modern BI tools still use it to combine individual observations by time or geography. That matters in large markets. California's population was approximately 39.0 million in 2023 according to the reference discussed in Wikipedia's overview of aggregate data, which is exactly why planners rely on county, city, and statewide summaries instead of raw person-level lists.
RevOps has the same scale problem. Once your CRM holds meaningful volume, nobody can manage the business from individual rows alone.
What aggregation does well
Aggregation is the engine behind the metrics leaders use:
- Trend tracking over months, quarters, and years
- Territory comparisons by region, segment, or owner
- Capacity planning for pipeline coverage, service load, or campaign volume
- Forecast visibility through grouped opportunity values and stage movement
This is why dashboards matter. Done well, they create a shared operating picture across marketing, sales, and customer teams.
What makes summary reporting valuable
The primary benefit isn't just convenience. It's speed with structure.
A good aggregate view helps teams answer questions such as:
- Are inbound channels creating enough qualified volume?
- Which segments are carrying most of open pipeline?
- Is service demand concentrated in one queue?
- Are certain regions underperforming against plan?
Those are strategic questions. Raw records alone won't answer them fast enough.
Teams need aggregate reporting because strategy happens at the level of patterns, not at the level of one contact record.
The key is to treat aggregate metrics as navigation tools. They point you toward pressure points. They don't replace diagnosis.
How to Implement Aggregation in Your Tech Stack
Most RevOps teams are already aggregating data every day. The issue isn't access. It's whether the logic is deliberate, documented, and stable enough to trust.

The important trade-off is that once data is grouped, you lose row-level variance. You can see the pattern, but not the individual deviations. That's why RudderStack's explanation of data aggregation is so useful for ops teams. It maps directly to how executives consume dashboards and how operators still need record-level detail for routing, triage, and scoring.
Salesforce patterns that work
In Salesforce, the cleanest native example is the Roll-Up Summary Field on a master-detail relationship. You can use it to:
- Sum closed won revenue from child Opportunities onto a parent object
- Count associated records such as assets, cases, or campaign members
- Capture min or max values like first purchase date or latest renewal date
That works well when the data model supports it. It breaks down when relationships are lookup-based or when the logic needs conditions that native roll-ups can't handle cleanly.
For those cases, teams usually move to one of three options:
- Custom report types and dashboard summaries for reporting-only needs
- Declarative Lookup Rollup Summaries or custom automation when the metric must live on the record
- Warehouse or BI-layer aggregation when logic spans multiple systems
If your sync architecture is messy, even a well-designed roll-up can fail because the source values arrive late, duplicate, or overwrite each other. That's why data synchronization strategy matters before you start building executive scorecards.
HubSpot patterns that work
HubSpot approaches aggregation differently, but the principle is the same. Teams commonly use:
- Calculated properties on companies or deals
- Association-based counts such as number of related deals or contacts
- Report builder summaries grouped by owner, source, date, or pipeline
A strong use case is a company-level property that counts associated deals, or a report that groups revenue by lifecycle stage progression. The summary is easy to consume. The risk comes when associations are inconsistent or when one object becomes the reporting anchor for logic that belongs elsewhere.
Think like a query designer
Behind the interface, aggregation always reduces to familiar database logic. Count records. Sum values. Group them by something meaningful.
You don't need to write SQL every day to think this way, but the design mindset helps:
- Choose the right grain. Are you reporting by contact, company, opportunity, or account?
- Define the grouping dimension. By owner, source, quarter, segment, or region?
- Control inclusion rules. Which stages, statuses, or date fields qualify?
For GTM engineering workflows, enrichment platforms such as Clay can also shape and combine records before they reach Salesforce or HubSpot. That can be useful, but it raises the bar for documentation. If enrichment logic changes upstream, your downstream aggregates can drift without anyone noticing.
Navigating Data Governance and Privacy Rules
Aggregation doesn't rescue weak source data. It amplifies it.
If sales reps use inconsistent opportunity stages, if lead source values drift, or if teams create duplicate companies with slightly different naming conventions, your dashboard will still produce neat totals. They just won't be trustworthy totals. That's why governance has to start before the report layer.
Governance first, dashboards second
For RevOps teams, good governance usually means a few unglamorous disciplines done consistently:
- Controlled field values so source, region, segment, and status fields don't fragment
- Clear ownership rules for who can edit lifecycle and pipeline fields
- Validation and review routines to catch exceptions before they hit leadership dashboards
- Shared metric definitions so marketing, sales, and finance aren't using the same label for different logic
If your team is tightening standards across Salesforce and HubSpot, a practical place to start is this guide to data governance best practices. The mechanics of picklists, sync rules, and ownership models matter more than most dashboard projects admit.
Aggregate does not always mean anonymous
This is the privacy nuance many teams miss. Aggregate data is often safer to share, but it isn't automatically anonymous.
A common gap in understanding is that small subgroups can still be re-identified when a report is filtered too narrowly. That's especially relevant for teams working under California privacy expectations shaped by CCPA and CPRA. FanRuan's discussion of aggregate data is helpful on this point because it highlights the practical distinction between summarised data and fully anonymised data.
Here's what that looks like in RevOps practice. A dashboard tile that shows performance for a very narrow account subset, tiny geography, or unusual industry grouping may point straight back to a single customer or prospect. The report may be aggregated in form, but not in outcome.
If a summary can still be tied back to one person, account, or tiny subgroup, you should treat it as sensitive.
For teams reviewing website-level consent, policy language, and disclosure obligations alongside CRM reporting practices, this guide for business website privacy is a useful legal-oriented companion resource. It helps frame where operational reporting and privacy obligations intersect.
Troubleshooting Common Aggregation Pitfalls
Most reporting failures tied to aggregate data aren't technical in the narrow sense. They're modelling failures. The dashboard calculates exactly what the system was told to calculate. The problem is that the grouping logic, join path, or attribution rule doesn't match the business question.

Double-counting in joined reports
This is one of the most common issues in BI layers and CRM reports that span multiple related objects.
An account with several contacts and several opportunities can explode into repeated rows when both objects are joined carelessly. The summary total then inflates pipeline, engagement, or activity counts. Teams often spot this only after leadership asks why one dashboard disagrees with another.
A good test is simple. Pull a small sample of accounts and reconcile the grouped result back to the underlying records. If the summary can't be explained from the row level, the join logic is probably wrong.
Attribution that rewards the wrong touch
Attribution reports are full of aggregate numbers that look decisive. “Leads by last-touch channel” or “revenue by source” can be useful, but they often collapse a longer buyer journey into one reporting shortcut.
That doesn't make the report useless. It means you have to read it for what it is. A last-touch aggregate is a summary of the final recorded interaction model, not a full account of influence.
The average that hides operational pain
Aggregation can mislead in diverse markets, often causing regional GTM planning to go sideways, because a broad average hides local variance. EdGlossary's explanation of aggregate data is especially relevant. It notes that high-level averages can create statistical blur in places like California, where metro areas can behave very differently.
For RevOps, that means a single statewide or national figure may be too coarse for action. If Bay Area performance, Southern California conversion, and Central Valley coverage are materially different, one rolled-up metric won't tell you where to intervene.
A practical troubleshooting checklist
When a dashboard feels wrong, use this sequence:
- Check the grain: confirm whether the report is based on leads, contacts, companies, accounts, or opportunities
- Inspect join paths: make sure one-to-many relationships aren't multiplying rows
- Review filter logic: date fields, lifecycle stages, and exclusion rules often drift
- Segment before concluding: break summary metrics by region, owner, segment, or industry
- Keep drill-down available: every executive metric should have a path back to record detail
Good aggregate reporting gives you a headline and a way to verify the headline.
If your Salesforce or HubSpot dashboards look tidy but still create arguments in pipeline meetings, that usually means the reporting layer needs stronger logic, not more charts.
If your team needs cleaner Salesforce or HubSpot reporting, stronger attribution logic, or a full RevOps audit of how summary metrics are built, MarTech Do can help you untangle the data model, fix dashboard trust issues, and turn aggregate reporting into something your revenue team can use.